TinyML That Can be Updated Without Resynthesizing or Rebooting the FPGA
Provide a Simple and Future-Proof Approach to Incorporating ML in a Variety of Systems

FPGA chips are projected to dominate IoT endpoint Deep Neural Nets (DNN) by the end of this decade [1]. They are more energy-efficient and faster than microcontrollers and easier to develop than ASICs. Infxl has teamed up with Microchip to speed up their adoption by offering two technological advantages:
1. Simple tools for going from training data to a compact DNN in C to HLS
2. TinyML FPGA implementation that can be updated without requiring a resynthesis or reboot
The first of these addresses a common concern of the embedded developer community: the ML and FPGA tools require a level of expertise that is costly and difficult to find.
The second one addresses an issue that is inherent to Machine Learning (ML): ML solutions become stale after a while and require periodic rejuvenation. We present a DNN-on-FPGA design that ensures that DNNs can be updated without resynthesizing, reimplementing, or rebooting the FPGA.
The energy efficiency and speed advantage of FPGA implementations can be further magnified by using ML models that are simple and compact. Infxl net is one such model (example code [2]). It implements a fully connected DNN in simple C using 8/16-bit data paths, without using multiplications or any floating-point operations.
A key feature of the Infxl net is the clear separation it maintains between the network structure/parameters and the inference engine. We exploit this feature by keeping the parameters in LSRAM while implementing the engine with LUTs and FFs. This way, when we need to update a deployed Infxl net, we do not need to resynthesize, reimplement, or even reboot the FPGA. We simply update the parameters in LSRAM, and the FPGA almost immediately starts delivering improved results based on the updated network structure/parameters .
The development process consists of two main steps:
• Upload preprocessed data to cloud.infxl.com and download the trained Infxl net as ready-to-use C code. This process does not require any background in ML.
• Use Microchip's easy-to-use SmartHLS compiler [3] to generate HLS from C code according to the exact requirements of the project. SmartHLS is an Eclipse-based IDE that takes C/C++ code as input and generates a SmartDesign IP component (Verilog HDL) as output. We can instantiate the generated SmartDesign IP component in the SmartDesign canvas available in Libero SoC design suite [4] to build an FPGA system.
The Infxl net C code includes a testbench and a generic interface. A few simple modifications are needed before it can be deployed it in an FPGA:
• Define the preferred interconnect, e.g., register or AXI4 interface for the incoming sensor data.
• Define the mechanism for communicating the class predicted by the Infxl net.
• Change the memory type for the Infxl net to simulation-only and define a memory external to the C code but still inside the FPGA.
• Create a top-level function in the C code to incorporate the Infxl net. This will be the IP instantiated into the overall FPGA system afterward.
The default Infxl net C code interfaces the inference engine to inputs and outputs through a small amount of RAM. This is a typical approach for microcontrollers. For an FPGA implementation, it is more efficient to interact with a FIFO-like interface. Additional small functions were added to the default Infxl net C code to accommodate this. The code for the Infxl net’s inference engine, however, remained untouched.
See below for a comparison of the original and the modified C code.
Original:
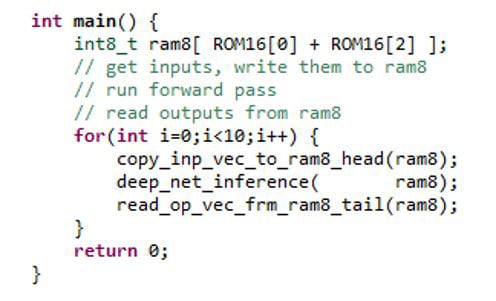
Modified:
The default testbench functions of the Infxl net, copy_inp_vec_to_ram8_head and read_op_vec_frm_ram8_tail, are modified or removed and a new function net_and_interface is introduced. net_and_interface is the top-level function that will be synthesized using SmartHLS. The function copy_inp_vec_to_ram8_head still takes the data from the testbench, however, it outputs data into the top-level function using the FIFO datatype. Data coming out of the FPGA-IP is read using the batch.read() command. The variable batch then sets the bit for the predicted class.
As the next step, the function-internal RAM gets extracted and will be converted to a simple memory interface during code generation by SmartHLS. This necessitates a simple modification of the ROM16 array. ROM16 encapsulates the structure as well all the parameters of the Infxl net. For a condition monitoring use case, the original ROM16 is modified as follows:
Original:

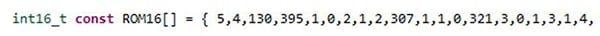
Modified:

In the testbench, ROM16 will be populated before the Infxl net is run. The equivalent loading is required in the full FPGA design as well. This loading mechanism also enables the updating of already deployed Infxl nets: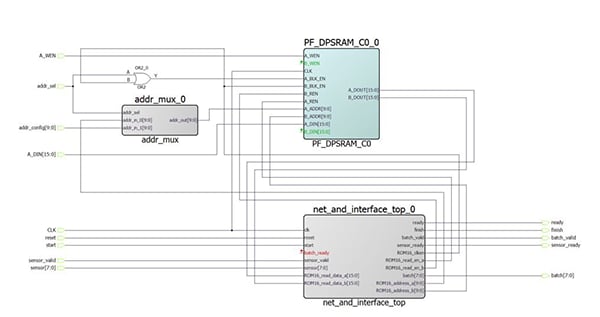
A multiplexer (MUX) is put into the address-path for one of the ports of the LSRAM. Together with those user-accessible addresses and the write-ports, the LSRAM can be filled and updated as required. The picture above shows the IP core with the Infxl net configured with FIFO-interfaces for both the sensor data and the recognized type of class. However, based on synthesis settings, this can be changed.
Let us look at the hardware now. The exact size of the IP core depends on the chosen interface and any required add-ons. An AXI4-interface, due to its additional interfacing capability, will require significantly more resources than a FIFO-like interface or a register interface connected to an AHB-bus. The configuration shown above will require approximately the following resources:
• 763 LUTs and 776 FFs for the IP including interfaces
• 546 LUTs and 610 FFs for Infxl net alone
In this configuration, inference on a single input vector takes approximately 2800 clock cycles. Running at 100 MHz or 200 MHz, this will result in a new classification every 28 µs or 14 µs, respectively.
When implementing in the way shown above, we can update the structure and parameters of Infxl net by replacing the existing ROM16 with an updated version. The exchange of the content-definition for the Infxl net takes one clock cycle per item in ROM16. In our use case, the length of the ROM16 array is 899. That equates to 899 clock cycles in which no recognition can be done. However, a faster switch between the new and old ROM16 can be made at the expense of some additional LSRAM. If continuous operation is desired, two parallel LSRAMs can be used. Out of the two, only one is active at any given time and the other is on stand-by. To update the Infxl net, the standby LSRAM is updated with a new ROM16. Afterward, a MUX in the output data-path of the LSRAMs is switched over, thus activating the newly loaded ROM16 and deactivating the previous one. This switch-over can be done within one clock cycle, resulting in an update without any practical delay.
If significantly more performance is required on the classification rate, the Infxl net can also be synthesized into a parallel structure up to full parallelism. This will lead to significantly faster classifications. This optimization is a trade-off between implementation size and performance. Moreover, a fully parallel implementation incorporates the structure and parameters of the Infxl net into the IP core itself. This removes the ability to do a simple update without a resynthesis and reboot. A fully parallel implementation of the use case that we have been discussing requires approximately 10900 LUTs and 4800 FFs, but speeds up the classification to approximately 600 clock cycles (including all handshaking).
In essence, Infxl net coupled with SmartHLS from Microsemi provides a simple and future-proof approach to incorporating ML in a variety of systems. The use case discussed in this article is based on data from a motion sensor. However, applications using Infxl net are not limited to that use case only. It can be employed for use cases ranging from predictive maintenance to environmental monitoring to robotics to malware detection to healthcare wearables and many more.
Notes:
[1] TinyML: The Next Big Opportunity in Tech (Published May 2021 by ABI Research https://www.abiresearch.com/market-research/product/7779411-tinyml-the-next-big-opportunity-in-tech/)
[2] https://cloud.infxl.com/infxltrainednetfpga
[3] SmartHLS™ Compiler Software
[4] Libero® SoC Design Suite Versions
Authors:
Martin Kellermann, Microchip Technology Inc.
Altaf Khan, Infxl