NAND Management and Data Retention Using Machine Learning Engine (MLE)
Integrating Machine Learning Engine (MLE) into end point storage devices such as NVMe® SSD allows data centers to use different Artificial Intelligence (AI) models for various applications, such as data management.

The integration of an MLE into NVMe SSD controllers represents a significant advancement in data storage technology. As AI continues to advance and SSD technology evolves, the application of AI/ML will be crucial in enhancing the reliability and efficiency of data storage solutions. This proactive, intelligent integration of MLE into NVMe solutions heralds a new era in data storage, introducing significantly enhanced performance and reliability with a wide range of applications.
NAND devices have a set number of Program-Erase cycles, known as PE cycles. Beyond this number, the NAND cell becomes unreliable and may lead to data corruption. Historically, techniques like BCH and LDPC error correction algorithms are used to mitigate this issue. There are other solutions such as Read Retry, which involves re-reading a cell multiple times to correct errors, but as NAND technology has advanced, this method has become insufficient in terms of endurance, data retention and power consumption. To address these growing challenges, machine learning is emerging as a revolutionary solution.
In the rapidly evolving field of data storage, a critical aspect of SSD performance is data endurance, which refers to the ability of the storage device to maintain data integrity over time. To address this, the integration of an MLE within NVMe SSD controllers is being explored to improve data retention capabilities.
The storage industry is increasingly adopting machine learning and AI to improve storage technologies, particularly in areas such as predictive maintenance, performance optimization and error correction. The integration of machine learning algorithms into SSD controllers enables the prediction and mitigation of potential data retention issues. Additionally, there is a growing focus on using machine learning to enhance error correction codes and data integrity mechanisms. By analyzing large volumes of operational data, machine learning can identify patterns and anomalies that traditional methods may overlook, resulting in more robust data retention strategies.
As NAND flash memory degrades over time, conventional error correction methods like BCH, LDPC and Read-Retry are insufficient to achieve the desired performance. To address this issue, we have developed a smart NAND management ML model that quickly predicts the optimal voltage threshold for accessing pages and retrieving data efficiently. Machine learning enables devices to make smarter decisions about how to read and write data, improving performance and reliability in ways that were not previously possible. This method enhances endurance in data retrieval and results in lower power consumption, as it requires fewer reads from the NANDs.
To achieve this, we trained the model by characterizing the NANDs throughout their end-of-life cycle and collecting data at different stages. We performed NAND measurements and generated a dataset to analyze the valley. For each reference in the valley dataset, we identified three suggested voltage thresholds (VTs) that fall under an error correction threshold. This data was then used to train the model.
The Neural Network is a fully connected network and is composed of an input layer, hidden layers and an output layer. The hidden layers have an activation function. Before entering/exiting the network, the input/output layer is scaled with mapping functions.
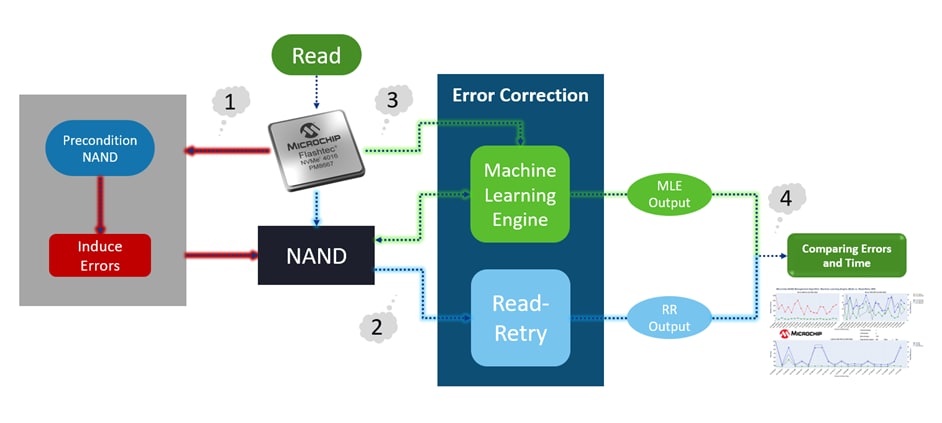
To test the model, we used preconditioned NANDs with induced errors, then used the MLE model and Read-Retry for error correction and compared the results.

- Each targeted page was selected randomly; for each point, the first read was done using Read-Retry, and the second read was done using MLE
- For each algorithm the data has been captured for comparison
- On the top-left graph, we are comparing the number of errors before (Red) and after applying MLE (Green), and it can be observed that the number of errors has significantly reduced when MLE is used
- On the top-right graph, we are comparing the number of errors after using RR (Blue) and after applying MLE (Green). The dotted line also indicates the error efficiency of MLE compared to RR
- On the buttom graph, we are comparing the latency for error correction using RR (Blue) and MLE (Green). The dotted line also indicates the time efficiency of MLE compared to RR